If you are reading this, you probably believe that the hard part of using a thousand GPUs is the code. You have seen the diagrams of data parallelism and tensor parallelism and pipeline parallelism, you have heard people talk about NCCL all-reduces and sharded optimizers, and the whole thing has the texture of a deep engineering problem that only a few elite labs have truly cracked. So when a project needs to scale, the instinct is to hire the parallelism wizard, the person who can wire up Megatron and ZeRO and make the GPUs talk to each other without deadlocking.
I want to argue that this instinct is mostly wrong, and that it gets the problem backwards. The engineering of multi-GPU scaling is, for the cases almost everyone cares about, a solved problem. The recipes are published, the libraries are mature, and the achievable efficiency has converged to a narrow band that has not moved much in years. What decides whether your thousand GPUs are worth owning is not how cleverly you split the model across them. It is whether you can keep them full. And keeping them full is not an engineering question. It is an economics question, and it is governed by a single hard constraint that no kernel can fix.
Here is that constraint, and it is the spine of everything that follows. A GPU is a fixed cost pretending to be a variable one. You pay for the whole chip, all the time, whether it is computing or idle. So the only number that ever matters is the fraction of the chip you actually use, and that fraction is bought with demand, not with code. Once you see scaling this way, the parallelism stops looking like the interesting part, and the boring questions, how much work do I actually have and how steadily does it arrive, turn out to be the ones that decide everything.
Start with the part that everyone treats as hard, because it is the part that is actually finished. There are three ways to spread a model across GPUs, and they compose. Data parallelism puts a full copy of the model on each GPU and feeds each copy a different slice of the batch, then averages the gradients. Tensor parallelism splits a single matrix multiply across several GPUs so they each hold a shard of the same layer. Pipeline parallelism cuts the model into stages along its depth and streams microbatches through them like parts down an assembly line. You pick a rectangle of these three to fit your model and your network, and that is the whole game.
The reason I say this is solved is that the published numbers stopped surprising anyone a while ago. When NVIDIA and the Megatron-LM team trained GPT-scale models across a cluster of A100s, they reported weak-scaling results from a 1.7-billion-parameter model on 8 GPUs all the way up to a one-trillion-parameter model on 3,072 GPUs. The thing to notice is not the size. It is how little the per-GPU efficiency moves across that entire range.
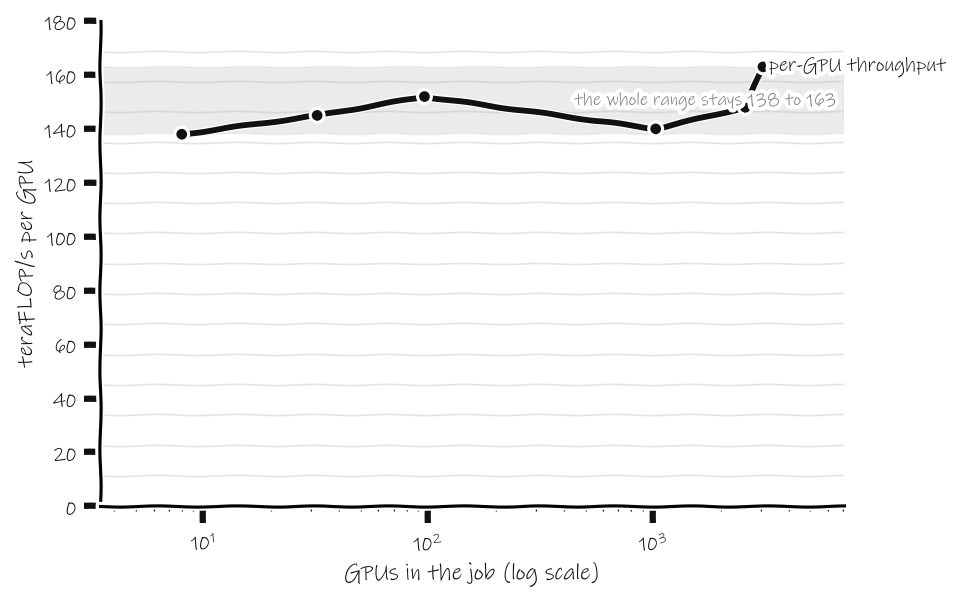
Figure 1: Per-GPU throughput traces a nearly flat line, staying inside a narrow 138 to 163 teraFLOP/s band, as the job grows from 8 GPUs to 3,072 along a log scale. That is near-linear weak scaling across a 384-fold increase in machine size, which is what a solved engineering problem looks like. Source: Narayanan et al., “Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM,” SC 2021 (arXiv:2104 .04473), Table 1.
A 1.7-billion-parameter model on 8 GPUs ran at 138 teraFLOP/s per GPU, about 44 percent of the A100’s theoretical peak. The trillion-parameter model on 3,072 GPUs ran at 163 teraFLOP/s per GPU, about 52 percent of peak. You added 384 times as many GPUs and the per-chip throughput went up, not down. That is what near-perfect weak scaling looks like, and it is remarkable, but it is remarkable in the way that a paved road is remarkable. Someone did the hard work once, and now you drive on it.
This convergence is not an accident, and it is worth understanding why it happened. There is essentially one good way to arrange these three kinds of parallelism for a given model and network, and the constraints that pick it are physical. Tensor parallelism needs the fastest possible link between GPUs because it communicates inside every layer, so it belongs inside a single server where the GPUs share NVLink. Pipeline parallelism tolerates slower links because it only passes activations at stage boundaries, so it spans servers. Data parallelism sits on the outside because it only synchronizes once per step. The good configurations are the ones that respect this hierarchy, and there are not many of them. When OpenAI or anyone else describes their training stack, the design is not novel, because there is barely any room for it to be novel. It is the configuration the hardware forces on you, implemented carefully.
So when a team tells me they need a parallelism expert to scale, my first question is whether they have an unusual model or an unusual network. If the answer is no, and it almost always is no, then they do not have an engineering problem. The Megatron and DeepSpeed recipes already encode the answer. They have a different problem, and they have not named it yet.
The number that the marketing department wants you to look at is peak FLOPS. The number that decides whether your cluster was a good idea is utilization, the fraction of that peak you actually convert into useful work. These two numbers are not close to each other, and the gap is not a rounding error. It is most of the chip.
The honest measure here is Model FLOPs Utilization, or MFU: the floating-point operations your model mathematically requires, divided by the operations the hardware could have done in the same wall-clock time. It strips out the recomputation and the overhead and asks the only question an accountant would ask, which is how much of what you rented did you use. The published MFU numbers for the most carefully engineered training runs in the world are sobering.
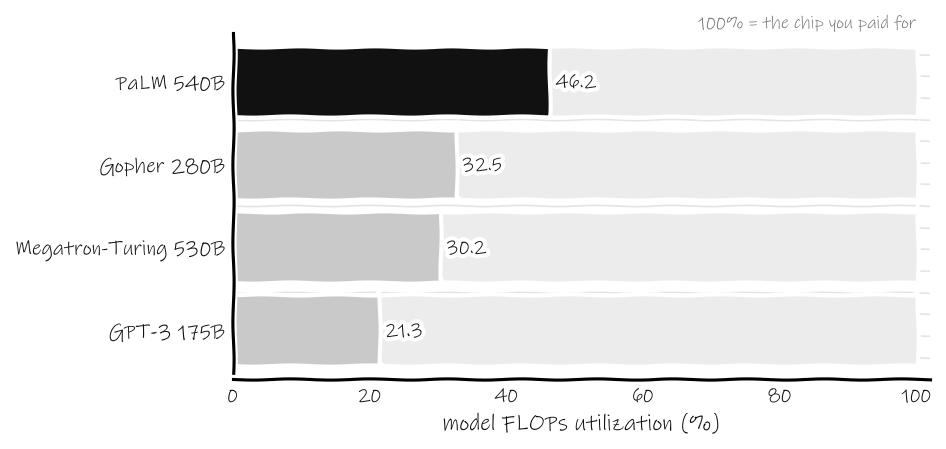
Figure 2: Model FLOPs utilization for four flagship training runs, each bar drawn against the full 100 percent it was billed for. GPT-3 used about a fifth of its hardware. Even PaLM, built by Google on TPU v4 with a compiler team behind it, used under half. The grey track behind each bar is the rest of the chip: paid for, and left idle. Source: Chowdhery et al., “PaLM: Scaling Language Modeling with Pathways” (arXiv:2204 .02311), MFU comparison table.
GPT-3 ran at an MFU of 21.3 percent. Megatron-Turing NLG, a 530-billion-parameter joint effort, managed 30.2 percent. Gopher reached 32.5 percent. PaLM, which Google engineered hard for utilization with a custom parallelism layout and the XLA compiler doing aggressive work underneath, hit 46.2 percent, and that was celebrated as a triumph. The best-resourced lab in the world, optimizing for exactly this, used less than half of the silicon it paid for. The other half ran hot, drew power, depreciated on schedule, and produced nothing.
This is the same trap I keep coming back to when people get excited about exaflops on a chip. You can build a chip with enormous peak throughput, but if you cannot feed it, the peak is a fiction. The bottleneck is never the production of FLOPS. We are extremely good at producing FLOPS. The bottleneck is keeping the arithmetic units fed with data, and at the cluster level the same logic repeats one rung up: the bottleneck is keeping the GPUs fed with work. Utilization is the name for how well you are doing that, and it is the only efficiency number that survives contact with a finance spreadsheet.
So the invariant is this. A GPU you cannot keep full is a GPU you are paying for and not using. Everything about scaling that actually matters is downstream of that sentence.
Here is the economic fact that the engineering framing hides. When you buy or rent a GPU, you pay for the device, not for the computation. A rented H100 costs the same per hour whether it is running at 60 percent utilization or 6 percent. An owned one costs you its purchase price amortized over its life, plus power and cooling and the data-center slot, and that bill arrives on a schedule that has nothing to do with how busy the chip was. The FLOPS are not metered. The clock is.
This is what I mean when I say a GPU is a fixed cost pretending to be a variable one. It looks like a variable cost because it does variable work, but the money leaves your account at a fixed rate. A chartered plane is the cleanest analogy I know. Once you have chartered it, the cost of the flight is set. Whether you fill every seat or fly it empty, you pay the same. The per-passenger cost is therefore not a property of the plane. It is a property of how many passengers you found. A full plane is cheap per head and an empty one is ruinous, and the plane is identical in both cases.
A GPU works exactly like that plane, and the seats are the slots in its compute and memory that a unit of work can occupy. The chip bills you by the hour. Your cost per useful operation is the hourly bill divided by the useful operations you managed to extract in that hour. Double the useful operations and you halve the unit cost, using the same chip, the same power draw, the same depreciation. Halve them and you double your cost. The hardware never changed. Only the fullness changed.
This reframes the entire scaling question and it is why I insist it is economics and not engineering. Adding GPUs does not add value. Adding GPUs adds fixed cost. The value only appears if the new GPUs are full, and whether they are full has nothing to do with how elegantly you sharded the model. It has to do with whether you brought enough work to the machine to occupy what you just bought. A second chartered plane is a liability until you have the passengers to fill it, and a thousand-GPU cluster is a liability until you have the work to fill it. The parallelism library will happily spread your job across all thousand. It cannot tell you whether you should have.
Now I can be concrete about where utilization actually comes from, and it is here that the word economics earns its place, because the lever is demand. The clearest case is inference, because inference is where most GPUs spend most of their lives and where the fixed-cost trap bites hardest.
A language model generates text one token at a time, and each token requires reading the entire model’s weights out of memory. If you serve one user, you read all those weights, do a tiny amount of arithmetic for that single sequence, and throw the read away. The arithmetic units sit almost completely idle while the memory system does all the work. This is the worst possible way to use the chip. The fix is batching: serve many users at once, so that one expensive read of the weights is amortized across many sequences. The reads stay roughly constant while the useful arithmetic multiplies. Utilization climbs because you finally gave the arithmetic units something to do.
The size of this effect is not subtle.
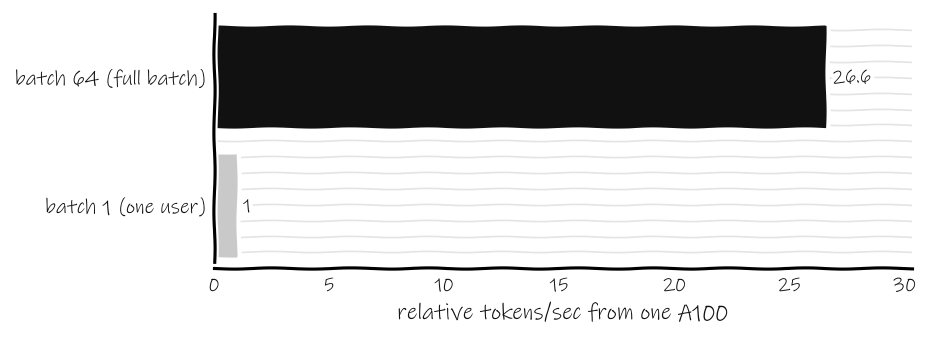
Figure 3: On an A100 serving a transformer at a 2,048-token length, moving from a batch of 1 to a batch of 64 raises throughput by about 27 times from the same chip. The hardware is identical in both bars. The only thing that changed is how many users showed up at once. Source: DatabaseMart vLLM A100 80GB benchmark, 2024.
The same A100 produces roughly 27 times more tokens per second at a batch of 64 than at a batch of 1. Nothing about the chip changed. You did not overclock it or upgrade its memory. You filled it. Measured as raw utilization, a small-batch decode can run as low as around 1 percent of the GPU’s capability, while a well-fed decode tops out near 50 percent. The factor between those two states is enormous, and it is set entirely by how much concurrent work you have, which is to say by how many users are talking to the model in the same window of time.
This is the hinge of the whole argument. To fill a batch you need concurrent requests, and concurrent requests are a user base. Utilization is therefore not something you engineer. It is something you attract. A model with a million simultaneous users keeps its batches full without trying, and runs near the efficient end of that range. The identical model with a hundred sporadic users runs near the empty end, on the identical hardware, at many times the cost per token. I have watched people search for the inference optimization that will close that gap, and they are looking in the wrong place. The gap is not a software defect. It is an absence of demand.
The economics get sharper when demand is uneven, because real traffic is spiky. A workload that arrives in bursts underfills its batches most of the time and then briefly overflows them, and across the day it runs three to five times worse than the published peak throughput. If your cluster sits at a 40 percent duty cycle, which is ordinary for anything facing real-world traffic, your true cost per million tokens is about two and a half times what the clean benchmark promised. The benchmark measured a full plane. You are flying a half-empty one most of the day, and the difference is your money.
Follow this one more step and it explains something about the industry that the engineering framing cannot. People assume the large labs have an infrastructure advantage, some secret in how they wire up their data centers. I do not think that is where their advantage lives, and the labs themselves have said as much when they describe stacks that are, technically, the obvious configuration. Their real advantage is the crowd.
A frontier lab serving a model to tens of millions of users gets high utilization for free, because demand at that scale is smooth and never lets the batches drain. The same deployment, the same model, the same code, handed to a company with a thin and bursty user base, runs at a fraction of the efficiency and several times the unit cost. The hardware does not know the difference. The economics know everything. This is a network effect dressed up as a technical moat, and it is why a large user base is itself a cost advantage, independent of any cleverness in the stack.
This also explains the puzzle of why open-weight models have not displaced the closed labs as fast as their quality would suggest. You can download a 400-billion-parameter model that rivals the frontier and run it yourself. What you cannot download is the crowd that makes it cheap to serve. An efficient large-scale deployment needs enough simultaneous traffic to keep its batches full and its expensive cross-GPU communication overlapped with useful work, and most people who self-host do not have that traffic. So they pay the empty-plane price, conclude that open weights are expensive, and go back to the API, where someone else’s crowd is subsidizing the utilization. The model was free. The demand was not, and the demand was the actual cost driver all along.
The unstable part of this, and the reason I think the frontier advantage is more fragile than it looks, is that the demand threshold for efficiency is a software number, not a law of nature. The current serving stacks become efficient only at large scale. If a better inference stack lets a 300-billion-parameter model reach high utilization at a smaller batch, the crowd you need to break even shrinks, and the frontier lab’s economic moat narrows accordingly. The moat is real today. It is made of demand, and the amount of demand it takes to cross it is exactly the kind of thing good engineering can lower.
I do not want to overstate this, because there is real engineering left and it would be dishonest to wave it away. The point is not that code is worthless. The point is that code operates on the margins of a problem whose center is economic, and it is worth being precise about which margins.
The sharpest remaining engineering constraint is physical and it sits right at the boundary I mentioned earlier. Tensor parallelism communicates inside every layer, so it has to live where the links are fastest. The Megatron results show that tensor parallelism is efficient only up to the number of GPUs in a single NVLink-connected server, which on those systems is 8. Push it past that boundary, so that a single matrix multiply is split across GPUs in different servers talking over slower links, and the throughput falls off a cliff, because now the slow inter-node network sits in the middle of your hottest communication path. This is a genuine engineering rule with a hard edge, and getting it wrong will wreck your efficiency no matter how much demand you have. But notice what kind of rule it is. It is a rule you follow, not a frontier you push. The answer is known. You just have to respect it.
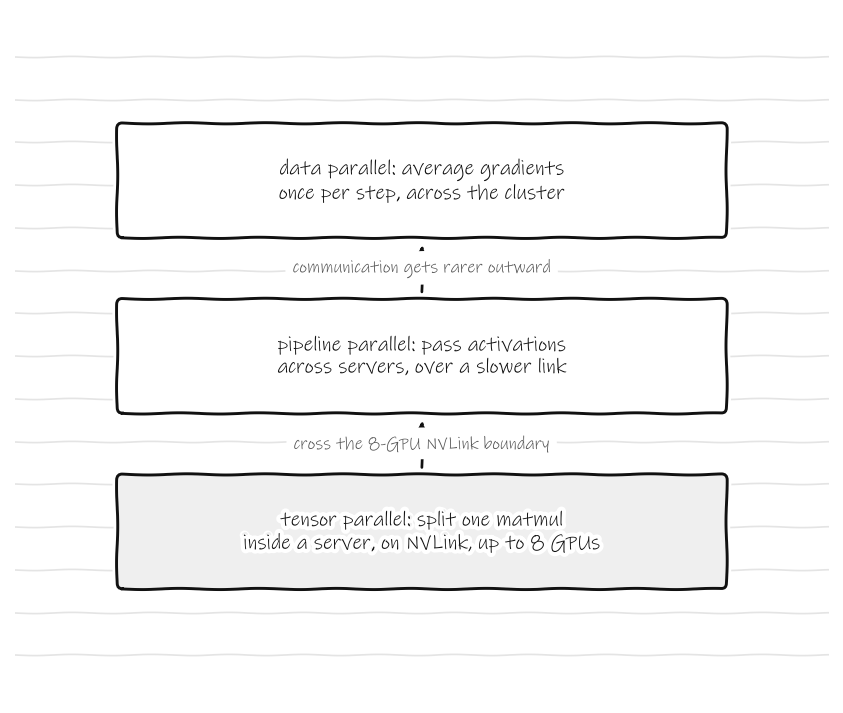
Figure 4: Why there is essentially one good layout. Each kind of parallelism sits where its communication can afford to live. Tensor parallelism talks inside every layer, so it has to stay on the fast NVLink inside a single server, which is the hard 8-GPU boundary at the bottom: split one matrix multiply past it and throughput falls off a cliff. Pipeline parallelism only passes activations at stage boundaries, so it tolerates the slower link between servers. Data parallelism synchronizes once per step, so it sits outermost. The hierarchy is dictated by the hardware, not chosen. Source: structure described in Narayanan et al., Megatron-LM, SC 2021 (arXiv:2104 .04473).
The other place engineering pays is in lowering the demand threshold for efficiency, which is the same lever I described as the frontier lab’s vulnerability. Shuttling key-value caches between GPUs efficiently, overlapping communication with computation, packing requests of different lengths into the same batch, serving prefill and decode on separate hardware so neither starves the other: this work is real and it matters, and it is some of the most valuable engineering in the field right now. But look at what it actually does. It does not raise the ceiling on a full machine by much, because a full machine is already near the physical limit. What it does is let you reach that ceiling with less demand, by making smaller and burstier workloads behave more like big smooth ones. It is engineering in service of economics. It moves the break-even point. It does not change the fact that a break-even point, measured in demand, is what you are managing.
So the engineering that remains is bounded on one side by physics, the hardware will not exceed its own limits, and aimed on the other side at an economic target, the demand you need to be efficient. That is a very different picture from the one where scaling is a deep technical mystery. The mystery is solved. What is left is a cost-engineering problem whose units are dollars and whose driver is how full you can keep the machine.
Let me turn this into something you can use, because a mental model is only worth the decisions it changes. When you are deciding how many GPUs to scale to, the question you were taught to ask is “can I parallelize my workload across N GPUs.” The Megatron and DeepSpeed recipes have already answered that one: yes, you almost certainly can, up to scales far beyond what you need. So stop asking it. Ask the economic question instead. Can I keep N GPUs full.
This flips the sizing decision. Cluster size should be set by sustained demand, not by model size. A bigger model does not justify more GPUs. Enough steady work to fill them justifies more GPUs. If your demand is small or spiky, fewer GPUs run at high utilization will beat more GPUs run at low utilization on every axis that matters, cost per token, cost per training step, and the depreciation you are eating either way. The instinct to add hardware when things feel slow is often exactly backward, because added hardware that you cannot fill lowers your average utilization and raises your unit cost. Sometimes the right move when a cluster feels inefficient is to make it smaller.
There is a usable break-even test buried in the inference economics, and it is worth carrying around. Self-hosting a model only pays off above a utilization floor, and that floor depends on the model. A small 7-billion-parameter model needs to keep its GPU more than about 50 percent utilized to beat the per-token price of an API, because it is cheap to serve and the fixed cost dominates easily. A larger 13-billion-parameter model breaks even closer to 10 percent utilization, because each token does more useful work and amortizes the fixed cost faster. Before you stand up your own serving cluster, estimate your sustained utilization honestly, including the spiky hours and the dead nights, and compare it to that floor. If you cannot clear it, the API is not a compromise. It is the cheaper machine, because it is running on someone else’s crowd.
The general form of the test is the counterfactual that applies to every fixed cost. For any GPU you are about to add, ask what its utilization will be over its life, not at the peak hour but on average. If the honest answer is low, the GPU is a chartered plane with empty seats, and no parallelism library will sell those seats for you. You have to bring the passengers, and bringing passengers is a problem of demand and pricing, which is to say a problem of economics.
The engineering of multi-GPU scaling is finished for almost everyone who thinks they have an engineering problem. Data, tensor, and pipeline parallelism compose into a small number of good configurations that the hardware itself dictates, the libraries implement them well, and the achievable per-GPU efficiency has held in a narrow band from 8 GPUs to several thousand. That part is a paved road. You drive on it.
What decides whether scaling was worth it is utilization, and utilization is an economic quantity, not a technical one. A GPU is a fixed cost pretending to be a variable one: you pay for the chip by the clock, so your real cost is set by how full you keep it, and fullness is bought with demand. In training, that means matching cluster size to sustained work. In inference, it means that batching, and therefore a large concurrent user base, is the difference between using 1 percent of a chip and 50 percent of it, a factor that dwarfs anything the kernel can give you. The frontier labs’ advantage is mostly their crowd, the open-weight gap is mostly an absence of crowd, and the best remaining engineering is the kind that lowers the demand you need to be efficient.
So the next time a scaling decision lands on your desk, do not reach for the parallelism expert first. Reach for the utilization estimate. Ask how full the machine will be, on average, across the boring middle of the day. That number, not the wiring diagram, is the one that decides whether you should scale at all.
- Deepak Narayanan, Mohammad Shoeybi, Jared Casper, et al., “Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM,” SC 2021. The weak-scaling results and the tensor-parallel-within-a-node boundary. https://arxiv.org/abs/2104.04473 - Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, et al., “PaLM: Scaling Language Modeling with Pathways,” 2022. The source of the Model FLOPs Utilization comparison across GPT-3, Gopher, Megatron-Turing NLG, and PaLM. https://arxiv.org/abs/2204.02311 - Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, Yuxiong He, “ZeRO: Memory Optimizations Toward Training Trillion Parameter Models,” SC 2020. The data-parallel memory sharding that makes large data parallelism practical. https://arxiv.org/abs/1910.02054 - Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, et al., “Efficient Memory Management for Large Language Model Serving with PagedAttention” (vLLM), SOSP 2023. How modern serving stacks raise inference utilization. https://arxiv.org/abs/2309.06180 - DatabaseMart, “vLLM GPU Benchmark on A100 80GB,” 2024. The batch-size throughput measurements behind Figure 3. https://www.databasemart.com/blog/vllm-gpu-benchmark-a100-80gb - Introl, “Inference Unit Economics: The True Cost Per Million Tokens.” The duty-cycle and break-even utilization figures. https://introl.com/blog/inference-unit-economics-true-cost-per-million-tokens-guide